シェアする




Webサイトを運営していると、似たようなページが複数できてしまうことはありませんか?たとえばサイト内の検索結果ページや、類似テーマで作ってしまった古いコンテンツなど。「これは検索エンジンにクロールしてもらわなくて良い」というページは、どのサイトにもあるものです。会員限定ページや、サイトの評価に関係のないパラメータ付きのURLも、クロールされるメリットはないでしょう。むしろ、そんなページまでクロールされてはサーバーに負荷がかかり、表示速度が下がる可能性もゼロではありません。
本記事は、GoogleやBing、Open AIのGPTBotといった検索エンジンからのクロール範囲を管理したいときに役立つクローラー向けの制御ファイル 「robots.txt(ロボッツテキスト)」 を紹介します。専門的に聞こえますが、記述ルールは意外とシンプル。robots.txtの基本的な書き方とサンプルコードをご紹介するので、ぜひ活用ください。
目次
- robots.txtの用途とは
- metaタグ「noindex」との違い
- robots.txt と noindex の使い分け
- 基本編|robots.txtの構成と書き方
- クロールを拒否したい
- クロールを許可したい
- 応用編|さまざまな条件つきでの書き方
- Googleの検索用クローラーボットだけブロックしたい
- GoogleのAI学習用クローラーボットだけブロックしたい
- 主要なAIクローラーをまとめてブロックしたい
- サイトマップを指定したい
- あるディレクトリにおいて特定のクローラーにのみ許可したい
- PDFファイルのクロールを拒否したい
- 特定パラメータを含むURLを拒否したい
- 注意点と文法チェックの方法
- robots.txt を正しく使おう
robots.txtの用途とは?
robots.txtは、検索エンジンや生成AIのクローラー(ロボット)に「サイトのどこをクロールし、どこをクロールしないか」を理解させるためのテキストファイルです。
たとえば以下のような設定をしたいときに使います。
- 特定のページやディレクトリだけをクロールさせない
- 特定のページやディレクトリだけをクロールさせる
- 上記クロール可否をクローラーの種類ごとに設定できる
- サイトマップの場所を指定したい
なお、robots.txtはすべてのクローラーに対して有効なわけではありませんが、GooglebotやOpenAIのGPTBotは、robots.txtでクロールを制御できます。
※参考:
・Google検索セントラル「robots.txt の書き方、設定と送信」
・OpenAI Platform「Overview of OpenAI Crawlers」
metaタグ「noindex」との違い
robots.txtとmetaタグ「noindex」は混同されがちですが、両者の役割は異なります。
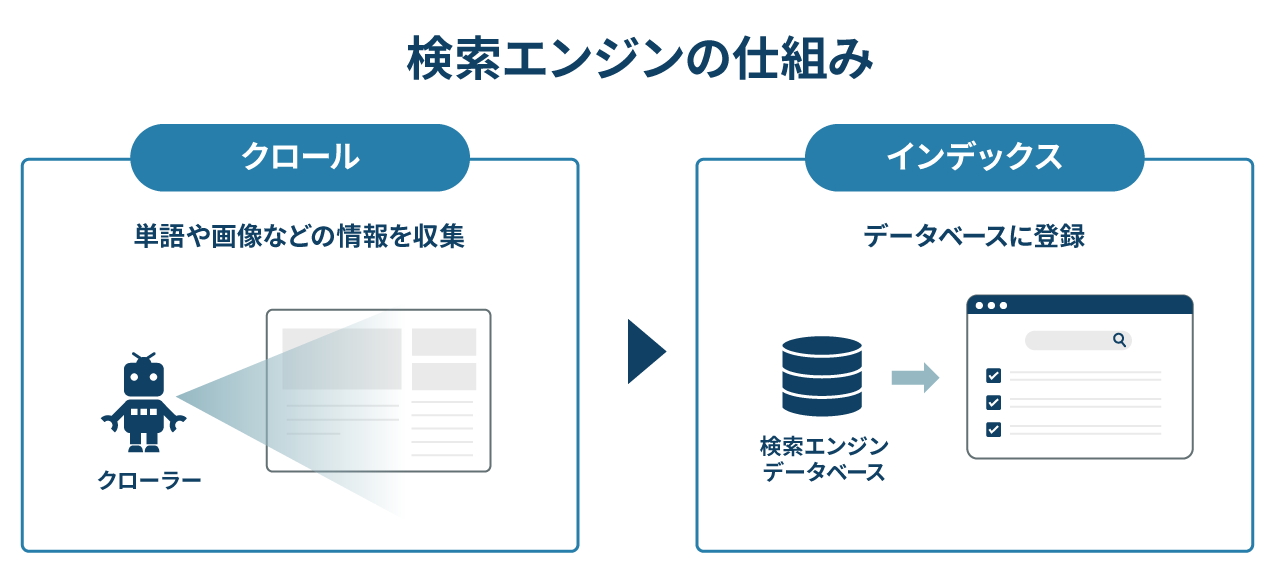
- robots.txt
- クローラーのアクセス自体をブロック
- metaタグ「noindex」
- クロールは許可したうえで、検索結果に表示されないように指示
※関連記事:
・クローラーとは?Web検索の仕組みをわかりやすく解説
・【2025年最新版】正しいSEOとは?5つのSEO対策とチェックリスト、最新事例
つまり、「クロールを制御する」のがrobots.txt、「インデックス登録を防ぐ」のがnoindexという違いがあるのです。
クローラーやnoindexなど、SEOの基本については以下で配布している無料の資料をご活用ください。
robots.txt と noindex の使い分け
robots.txtとnoindexは役割が異なるので、使い分けるのが基本です。
- noindex
- インデックス(検索結果への表示)制御したいときに使用
- robots.txt
- クロール(アクセス)制御したいときに使用
中小規模のWebサイトではクロール制御が必要なケースは稀なため、インデックスさせたくないページには基本的に「noindex」を使いましょう。robots.txtは設定を誤るリスクがある上、ブロックしてもインデックスされる可能性があるからです。(何らかの理由でnoindexを付与できないときは代替手段として使われることもありますが)
一方で、数百万ページを超える大規模サイトでは、「クロール最適化」のためにrobots.txtが活用されます。重要度の低いページへのクロールを制限することで、重要なページへクローリングを集中させることが可能です。
基本編|robots.txtの構成と書き方
robots.txtには、「どのクローラーに、どのページへのアクセスを許可・禁止するか」を記述しましょう。基本構成は次のとおりです。
| ルール | 内容 | 例 |
|---|---|---|
| User-agent | 適用先のクローラー名 | User-agent: Googlebot |
| Disallow | 後ろに続くパスのクロールを禁止にする | Disallow: /junk/ |
| Allow | 後ろに続くパスのクロールを許可する | Allow: /service/ |
| ワイルドカード * | すべてを対象にする または、特定のパターンに一致するパスを指定する | User-agent: * |
ここからは、よくあるケースを想定して、記述のサンプルを紹介していきます。
クロールを拒否したい
クロールを拒否したいときは、Disallowを使います。ページ単位はもちろん、ディレクトリごとにアクセスを拒否したいときにも使えます。
Disallow: /admin/
Disallow: /private.html
上記の記述では、クローラーの種類を問わず、「admin」配下すべてと、「private.html」へのクロールを拒否しています。
クロールを許可したい
クロールを許可したいときにはAllowを使用します。robots.txtを置かない限り、検索エンジンのクローラーは基本的に全ページをクロールしようとします。そのため、すべてのページを許可したいだけであれば、Allowの記述は不要です。
しかし、特定のディレクトリはクロール禁止にしつつ、その中の一部だけはクロールを許可したいというケースがあります。Allowはこのような場合に有効です。
Disallow: /admin/
Allow: /admin/help.html
上記の記述は、クローラーの種類を問わず、「admin」配下をクロールさせないようにしていますが、「admin/help.html」のみはクロールを許可しています。
応用編|さまざまな条件つきでの書き方
robots.txtは複数の指示を組み合わせることで、柔軟な設定が可能です。ここからは応用編として、さまざまな条件下での記述サンプルを紹介します。
※参考:Google検索セントラル「Google による robots.txt の指定の解釈」
特定のクローラーだけをブロックしたい場合は、以下のように記述しましょう。
Googleの検索用クローラーだけブロックしたい
たとえばGoogleの検索用クローラー「Googlebot」。この書き方をすれば、Googleの検索用ボットだけはサイト全体をクロールできないですが、その他のクローラーはサイト全体をクロール可能です。
Disallow: /
User-agent: *
Allow: /
GoogleのAI学習用クローラーボットだけブロックしたい
Googleは検索用のGooglebotとは別に、AI学習用のクローラー Google-Extended があります。記述時は間違えないように注意しましょう。GoogleのAI学習クローラーだけブロックしたいときは、以下のサンプルコードを参考に記述してください。
Disallow: /
User-agent: *
Allow: /
※これを記述しても、Google検索のクロールには影響しません。
主要なAIクローラーをまとめてブロックしたい
最近は「自社でお金や時間をかけて調査した情報を、生成AIに渡したくない」と考える企業も出てきました。robots.txtは、生成AIのボット・クローラーを制御するときも有効です。
たとえば以下のような主要AI開発企業は、自社のAIモデル学習用クローラーが robots.txt のルールに従うことを公式に表明しているからです。
主要AIクローラーとは?GPTBotGoogle-Extendedanthropic-aiCCBot※参考:
ChatGPTのウェブクローラはGPTBot。robots.txtでブロック可能|海外SEO情報ブログ(当社の執行役員・鈴木謙一 著)
主要AIクローラーをまとめてブロックしたいときの記述例は以下です。
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
サイトマップを指定したい
クローラーにWebサイト全体の構造を正しく理解してもらうために、サイトマップ(sitemap.xml)を明示的に伝えることができます。
書き方は以下の通りです(※User-agentの指定は不要です)。
[absoluteURL]には、サイトマップの絶対URL(完全なURL)を入れましょう。絶対URLとは、プロトコル(httpsの部分)やドメイン名を省略しないURLです。
あるディレクトリにおいて特定のクローラーにのみ許可したい
特定のディレクトリに対して、特定のクローラーのみにクロールを許可する場合は、次のように記述します。
Disallow: /private/
User-agent: hogehoge-bot
Allow: /private/
この例では、「hogehoge-bot」は「private」をクロールできますが、他のクローラーは「private」をクロールできません。
PDFファイルのクロールを拒否したい
PDFファイルのクロールを拒否したい場合は、次のように記述しましょう。
Disallow: /*.pdf$
ここでのドルマーク「$」は、URLの末尾を意味しています。この例では、全体のクロールは許可していますが、末尾が「.pdf」で終わるURLのみクロールできないようにしています。
PDF以外のファイルも、同様の方法で設定可能です。
▼gifファイル(.gif)へのクロールを拒否する場合:Disallow: /*.gif$
▼エクセルファイル(.xls)へのクロールを拒否する場合:
Disallow: /*.xls$
特定パラメータを含むURLを拒否したい
URLの後ろに特定のパラメータがついているURLのクロールを拒否したい場合は、次のように記述します。
Disallow: /*?hogehoge=
この例では、クローラーの種類を問わず、「?hogehoge=」というパラメータを含むURLのクロールを拒否します。
サイト内に同じ内容の別URL(パラメータ違い)があると、その分だけクローラーが巡回してしまいます。たとえばhogehoge= を含むURLと含まないURLが同じ内容を返すとき、検索エンジンに重複コンテンツとして扱われる可能性があります。
こうしたURLのクロールを制限することで、クローラーが本当に重要なページを優先して巡回できるようになり、結果としてクロール効率の向上につながります。
注意点と文法チェックの方法
robots.txtの設定はシンプルに見えますが、記述を誤ると意図しない動作を引き起こす恐れがあります。robots.txtの注意点と、robots.txtが正しく動いているかの確認方法についてもお伝えしておきましょう。
1.優先順位を理解する
robots.txtに記述されたルールには適用の優先順位があります。これは、複数のルールが同じURLにマッチした場合にどちらが適用されるかを決める仕組みです。Google検索セントラルでは、次のように定義されています。
robots.txt ルールと URL との一致判定を行う際、クローラーはルールのパスの長さに基づいて最も限定的なルールを使用します。ワイルドカードを含むルールが競合する場合は、最も制限の少ないルールを使用します。
※引用:Google による robots.txt の指定の解釈「ルールの優先順位」
例❶ 優先されるルールの違い
以下の場合「Allow: /p」が適用されます。なぜなら、対象範囲がより限定されているためです。その結果、/p で始まるURL(例:/page、/product など)はクロールが許可され、それ以外は拒否されます。なお、ルールを記述する順番を変えても、優先順位は変わりません。Disallow: /
例❷ ルールの競合
同じパスに対してAllowとDisallowを両方書くと、ルールが競合します。この場合、Googleは「より制限の少ないルール(=Allow)」を優先するため、「admin」へのクロールは許可されます。Allow: /admin/
Disallow: /admin/
この仕様を理解していないと、「Disallowを設定したのに、想定外にページがクロールされてしまう」といった事態につながりかねません。
robots.txtを編集する際は、ルール同士が矛盾していないか、優先順位の影響を受けていないかを必ず確認することが重要です。
2.ブロックしてもインデックスされる可能性がある
robots.txtでクロールをブロックしても、外部サイトからのリンクなどによってページがインデックスされてしまう可能性があります。
すでにインデックスされた不要なページを削除し、かつ今後のクロールも止めたい場合には、まずnoindexタグを検索エンジンに読み込ませてからrobots.txtでブロックします。これにより、ある程度インデックスされることを抑えることができます。
また、重複コンテンツについては、noindexやrobots.txtでの対処を検討する前に、重複が発生しない仕様にするなど、重複自体を解消する根本的な対策を優先しましょう。
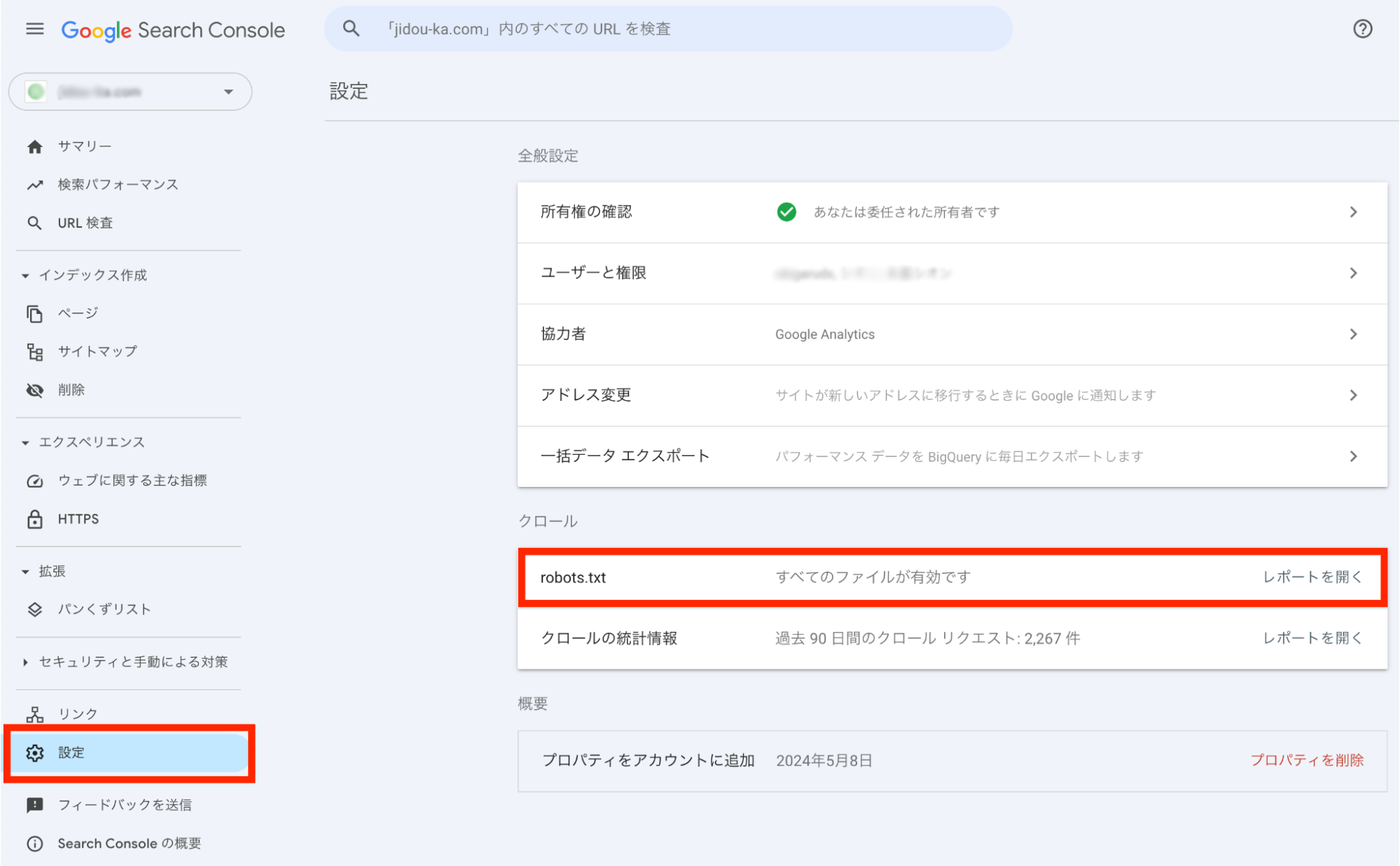
文法チェック:Googleサーチコンソールを使う
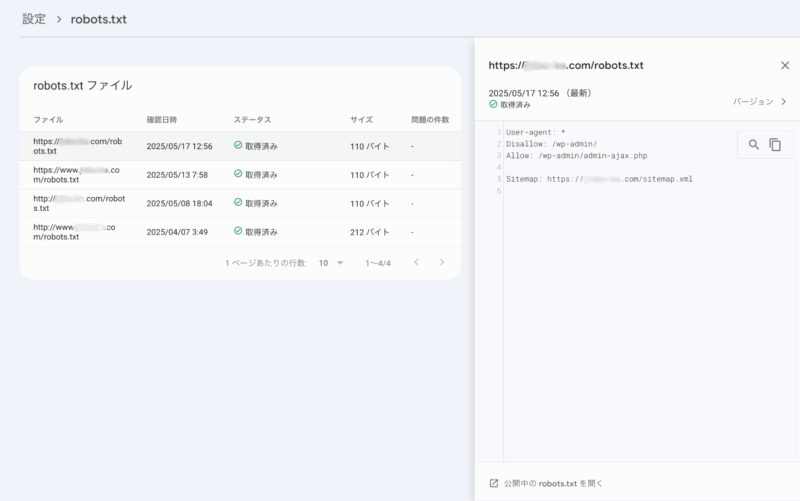
robots.txtの記述チェックには、Googleサーチコンソールが便利です。サーチコンソールの「設定」エリアにある「robots.txt」をクリックすると、robots.txtに関するレポートを確認できます。
エラーがある場合は「問題の件数」欄に数値が表示されるので、robots.txt更新後は確認してみてください。
なお、Googleが提供していた「robots.txtテスター」は、2023年12月12日に廃止されました。
※参考:
・Search Consoleヘルプ「robots.txt レポート」
・海外SEO情報ブログ「robots.txt テスターは廃止」
robots.txt を正しく使おう
robots.txtは、検索エンジンや生成AIのクローラーの動きを管理するテキストファイルです。
とくに大規模サイトにとっては、積極的な活用をおすすめします。
正しく設定すればサーバーの負荷軽減やセキュリティ面の向上にもつながります。
ただし設定をまちがえるとWebサイト全体が検索結果に表示されなくなるリスクもはらんでいる諸刃の剣でもあります。
不安や懸念点、robots.txtの対象ページで迷ったら設定の前に、当社・Faber Companyにご相談ください。テクニカルSEOを得意とするコンサルタントが、御社を支援します。


同志社大学在学中にインドで情報誌の立ち上げを経験。卒業後にレバレジーズ株式会社に入社。2016年にXINOBIX株式会社を起業し、インド進出支援業をスタート。その後、英会話スクールの比較サイトを起業しウェブリオ(現GLASグループ)に売却。その間、複数の企業でインハウスのSEO責任者や事業部長を経験。2021年に再度当社を専業とし、現在はコンテンツマーケティング支援業を行う。
X▶︎@gayan_x Facebook▶︎長屋智揮

2011年にFaber Companyに参画、SEOには10年以上従事。SEOコンサルティングチームのリーダーとして、多数の改善提案・実装支援の実績を持っている。特にデータベース型サイトの分析を得意とする。























