シェアする




クローラーは、検索エンジンにおいてWebページの情報を収集するためのプログラムです。スパイダーやロボットと呼ばれることもあります。膨大なインターネットを「リンク」を辿って巡回し、個々のWebページの情報を収集していきます。このことを「クロール」といいます。
本記事では、クローラーの種類や検索エンジンの仕組み、SEO対策におけるポイントについてわかりやすく解説します。
目次
クローラーとは?
クローラーとは、WebページのリンクをたどってWebサイトを巡回(クロール)し、ソースコードから画像や文章といった情報を自動的に収集するプログラムやツールのことです。「スパイダー」や「ロボット」と呼ばれることもあります。
クローラーは検索エンジンによって種類が異なり、たとえばGoogle検索では「Googlebot(グーグルボット)」というクローラーが巡回しています。
検索エンジンでは、最初にクローラーがリンクをたどってWebサイトを検出します。クローラーは取得した情報をもとにWebサイトの順位を評価し、検索結果に表します。つまり、クローラーにクロールされなければ、検索結果には表示されないということです。SEO対策を行う上で、クローラーの仕組みを理解しておくことは非常に重要です。
検索エンジンとクロールの仕組み
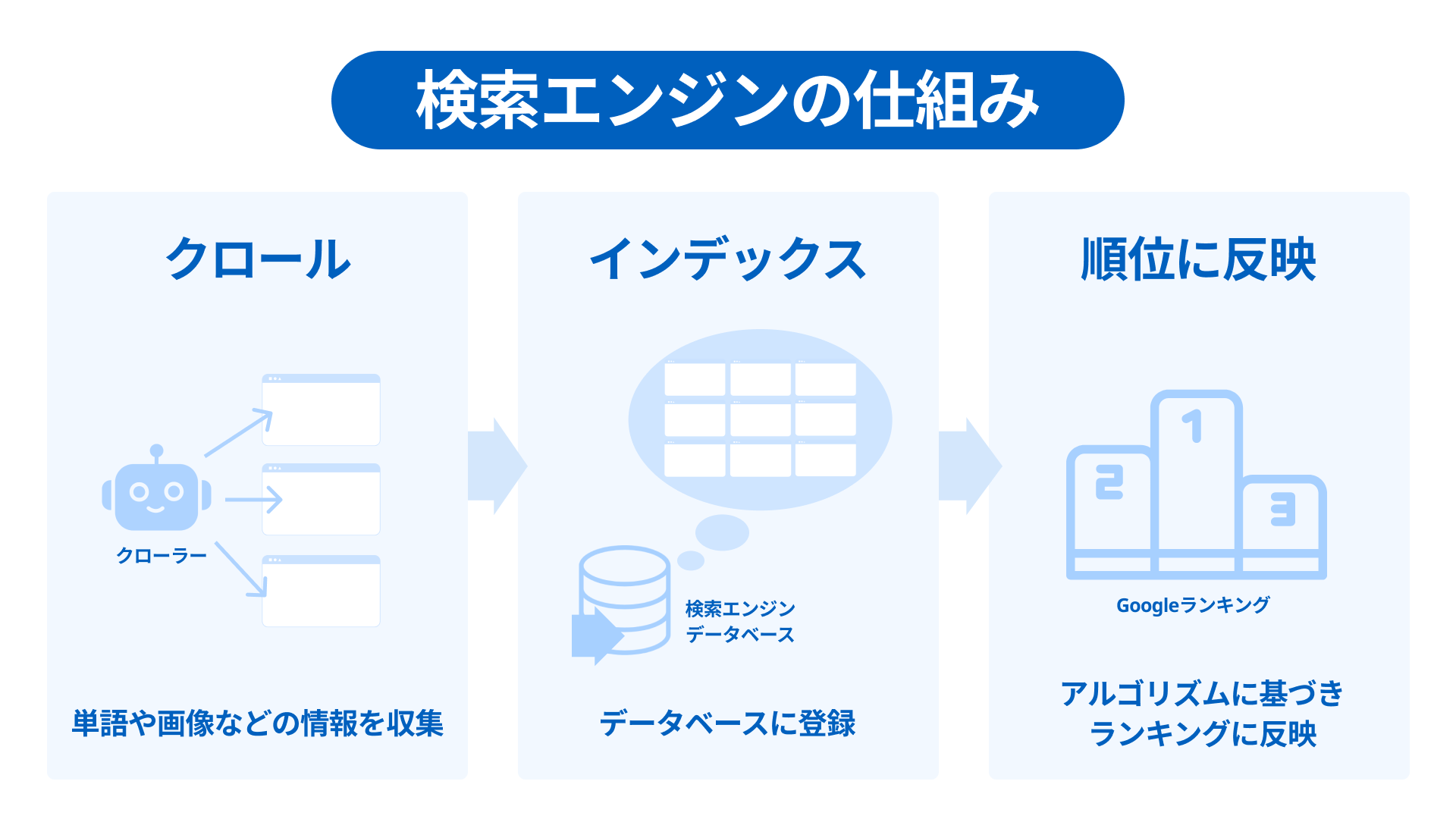
クローラーは膨大なインターネットを検索し、リンクを辿ってWebページの情報を収集します。これをクロールと言います。そしてWebページから、単語や画像などの情報を把握していきます。
その後、「検索インデックス」と呼ばれるデータベースに、Webページに含まれるすべての単語が1つずつ登録されます。Googleは単語以外にも画像やPDF、Webサイトの新しさといったさまざまな情報をインデックスし、アルゴリズムに基づき検索結果のランキングに反映します。
Googleは膨大なインターネット情報を巡回するために、常に数千台のマシンを使い同時にクロールを実行しています。
クローラーの確認方法
クローラーが巡回したタイミングやページごとのインデックス状況、エラーなど、クローラーのアクセス状況を確認する方法を紹介します。
URL検査ツールを使う
Google Search Consoleに標準搭載されている「URL検査ツール」を使うことで、ページ単位でインデックスの登録状況や直近のクロール状況が確認できます。
Google Search Consoleのメニューバーから「URL検査」をクリックし、上部の検索窓に状況を確認したいWebページのURLを入力します。すると、インデックスされているかどうかのステイタスが返ってきます。
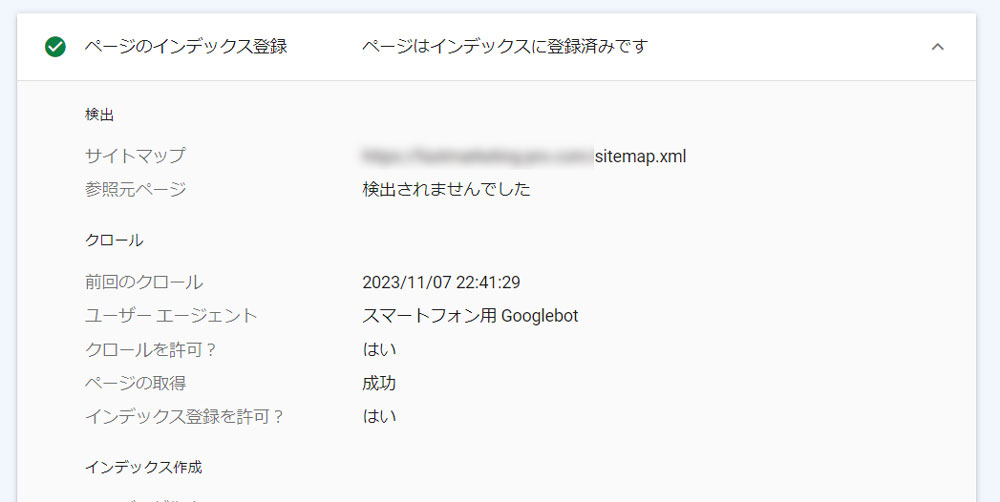
「ページはインデックスに登録されていません/登録されていますが問題があります」と表示されるときは、インデックス登録をリクエストできます。
また、インデックスの登録状況では、参照元ページや直近のクロール日時、ユーザーエージェント(クローラーの種類)なども確認が可能です。
クロール統計情報を確認する
Google Search Consoleの「設定」から「クロールの統計情報」を開くと、サイトに対するクロールリクエストの合計数や、ページの平均応答時間などを確認できます。
たとえば、Webページの数とクロールリクエストの数との乖離が大きい場合は、何らかの問題が起きている可能性があるため対処が必要だと判断ができます。
クローラーを拒否する方法
robots.txtでクロール不要なページをブロックすることが可能です。
「robots.txt(ロボッツドットテキスト)」は、Googlebotのアクセスを制御するためのファイルです。クロールしてほしくないページはrobots.txtファイルをサーバーにアップロードすることで、クローラーの巡回を止めることができます。robots.txtの各行は、「フィールド」「コロン(:)」「値(ページURLやクローラーの指定など)」の順で記述されます。
たとえば、Googlebotの/nogooglebot/のアクセスを拒否したい場合は以下のように記述します。
User-agent: Googlebot
Disallow: /nogooglebot/
クローラビリティを最適化する8つのポイント
「クローラビリティ」とは、クローラーがどの程度Webサイトを見つけやすいか(クロールのしやすさ)を表す言葉です。クローラビリティが悪いと、Webページがインデックスされないなどの問題が生じ、順位やアクセス数など、SEOに悪影響が出てしまいます。
クローラビリティを最適化する観点には、「クローラーに見つけてもらう」と「クロール効率を高める」の2つがあります。それぞれ、詳しく解説します。
クローラーに見つけてもらう
クローラビリティを最適化するには、クローラーに見つけてもらえるようこちら側から働きかける方法があります。
- 1. XMLサイトマップを作成し「送信」する
- 2. 「インデックス登録をリクエスト」を使用する
- 3. Webサイト内のリンクを適切に設定する
- 4. 外部リンクを獲得する(Webサイトの価値を向上させる)
1)XMLサイトマップを作成し「送信」する
XMLサイトマップを作成し、Google Search Consoleから送信すると、クローラーがWebサイトを発見しやすくなります。
XMLサイトマップとは、XML形式で作成されたサイトの目次のことです。XMLサイトマップがあることで、クローラーはサイト内のすべてのページを巡回でき、インデックスがスムーズに進みます。
WordPressなどのCMSには、はじめからクローラー用のサイトマップが用意されていることも多くあります。
クローラーはURLを辿ってさまざまなWebページをインデックスするので、外からリンクされていないWebページはクローラーに見つけてもらえない可能性があるので注意しましょう。
2)「インデックス登録をリクエスト」を使用する
Google Search Consoleの「インデックス登録をリクエスト(旧:Fetch as Google)」というフェッチャー機能を利用すれば、Webページ単位でクロールをリクエストできます。
通常、Webページを公開すると数日から数週間でインデックスされますが、あまりに遅い場合は、該当ページにクローラーがたどり着いていない可能性が考えられます。
Google SearchConsoleの「URL検査」を使うと、1ページ(URL)ごとにインデックス登録の有無が確認できます。もしインデックスされていないページが見つかれば、そのままGoogle Search Console上で「インデックス登録をリクエスト」するとよいでしょう。
3)Webサイト内のリンクを適切に設定する
クローラーがWebサイト内のリンクをたどりやすいように、Webサイト内の内部リンクを適切に設定することも重要です。内部リンクを設置することでGoogleクローラーの巡回経路が増えるため、インデックスされるまでの時間が早まるためです。
内部リンクを設置する際は、関連するコンテンツ同士を適切につなげることが大事です。ジャンルやカテゴリごとに記事をまとめることで、クローラーにWebページ同士の関連性も伝えることができるためです。
今閲覧しているページがWebサイト上どの位置にあるかを示した「パンくずリスト」の設置や、どのページからもリンクされないWebページを作らない、といった対策も必要です。このように内部リンクが正しく設定されていれば、大半の中小規模のWebサイトは問題なくクロールされます。
4)外部リンクを獲得する(Webサイトの価値を向上させる)
外部リンクを獲得することもインデックスを促進します。GoogleのクローラーはWebページの「人気度」や「ユーザー価値」をクロールの指標にしているためです。
最新情報を追加する、専門的な情報を増やす、オリジナリティを高めるなど、外部からリンクしてもらえるような有益なコンテンツを作成し、発信しましょう。結果的に被リンクの増加につながり、外部サイトからもクローラーがWebサイトを巡回しにくることが期待できます。
クロール効率を高める
クロール効率を高めることで、限られたクロールバジェットを有効的に使うことができ、クローラビリティを高められます。
- 5. リンク切れしているページをチェックし削除する
- 6. ソフト404エラーをなくす
- 7. 重複しているコンテンツをまとめるか削除する
- 8. ページ表示速度の改善
5)リンク切れしているページをチェックし削除する
リンク切れ(デッドリンク)しているページを無くすことで、クロールの「無駄打ち」を減らせます。
リンク切れしているWebページがあればリンクを削除するか、別の正しいページへリンクを修正します。ページのリンク切れは、Google Search Console上で簡単にチェックできます。
管理画面の「インデックス作成」メニューから「ページ」を表示すると、サイト内ぺージのインデックス状況が表示されます。理由の「見つかりませんでした(404)」に記載されているページがリンク切れのページです。
6)ソフト404エラーをなくす
ソフト404エラーとは、実際にはページURLやコンテンツが存在していないにもかかわらず、サーバーが「200(リクエストの成功)」を返してしまう現象です。
画面上にはエラー表示がされますが、サーバー上ではページが存在していると見なされます。本来は巡回を必要としないページですが、クローラーが訪れ無駄なクロールが生まれてしまいます。
ソフト404エラーは、Google Search Consoleで簡単にチェックできます。管理画面の「インデックス作成」メニューから「ページ」を表示した際、「送信されたURLはソフト404エラーのようです」というエラーが表示されます。
ソフト404エラーが発生してしまったページは、ページ自体が存在しないことを示す「404 Not Found」を返すように設定を変更しましょう。URLが更新されている、またはコンテンツが引っ越している場合は、URLの恒久的な変更を知らせる「301リダイレクト」を正しいページに設定するようにします。
7)重複しているコンテンツをまとめるか削除する
内容が重複しているページは、1つにまとめるか削除することでクロール効率を上げられます。またはリダイレクトを用いることで、ページが統合されたことをクローラーが把握できます。
たとえば、並び方だけが違う商品一覧ページで、並び順ごとにURLが生成されるような場合などです。具体的には、表示される商品が同じにも関わらず、下記のように並び順で複数のURLがある場合です。
- 価格で並び替えた際のURL:https://○○○.com/item/?=price
- 人気で並び替えた際のURL:https://○○○.com/item/?= popularity
この場合は、「?=」のURLをnoindexにする方法などもあります。
また「httpsの有無」の重複の一種です。同じ内容の
- SSL化されたURL :https://○○○.com
- SSL化されていないURLhttp://○○○.com
にそれぞれアクセスできたとします。この場合、同じコンテンツが2つ存在することになり、重複に該当します。httpsにある方に「301リダイレクト」することで重複を防ぐことができます。
8)ページ表示速度の改善
Webページの表示速度を改善することで、クロール効率を改善できます。GoogleのクローラーがWebページの情報を収集する際には、当然ながらGoogleのマシンのリソースを使用します。Webページの表示速度が早ければ早いほど、同じリソースで多くの情報を処理できます。
たとえば、PHPのバージョンやデータベースを改善することでサーバーのレスポンススピードを改善できる場合があります。Webページの読み込みを阻害する大きな画像やJavaScript、Webフォントなどの実装方法を見直すことも有効です。
ページ表示速度の改善はユーザー体験の向上にもつながるため、自社サイトの表示速度は定期的にチェックし改善しましょう。
クローラーの種類
Googleのクローラーには、収集するデータなどに応じて複数の種類があります。
| クローラーの種類 | 用途 |
| スマートフォン用「Googlebot」 | スマートフォン用 |
| デスクトップ用「Googlebot」 | デスクトップ用 |
| Googlebot-Image | 画像検索用 |
| Googlebot-Video | 動画用 |
| Googlebot-News | ニュース検索用 |
| Googlebot-Video | 動画用 |
| AdsBot-Google | PCの広告品質をチェックする |
| AdsBot-Google-mobile | モバイルの広告品質をチェックする |
なお、クローラーの一種に「フェッチャー」と呼ばれるプログラムがあります。フェッチャーとは、特定のWebページからデータを読み出すプログラムです。
たとえば、Googleには「URL検査ツール」と呼ばれるフェッチャー機能が付随しており、任意のページのインデックス登録をGooglebotにリクエストできます。
クローラーとフェッチャーの違いは、クローラーが自動的に情報収集を行うのに対し、フェッチャーはユーザーからのリクエストに基づき処理を行う点です。
クロールバジェットとは
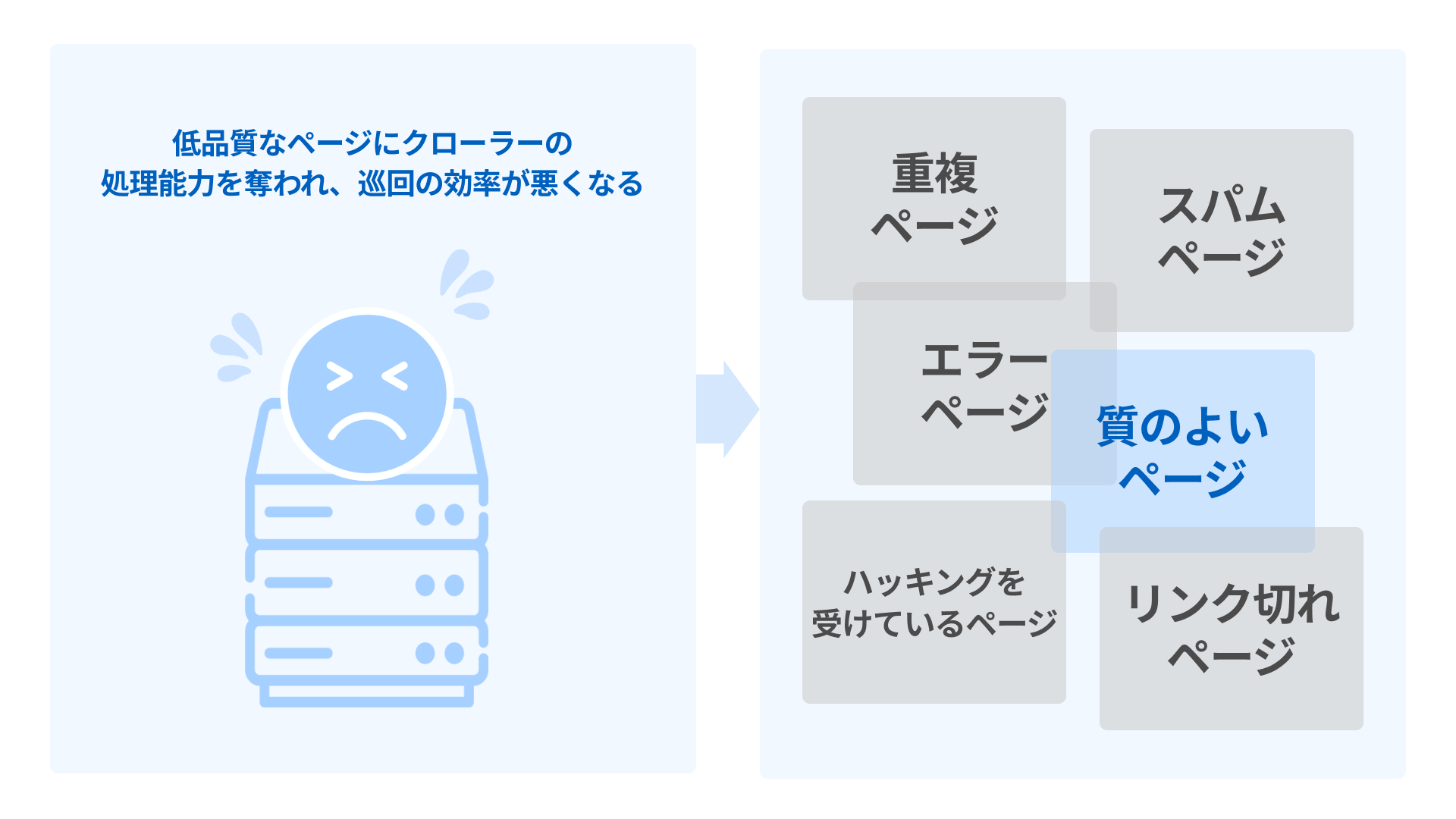
「クロールバジェット」とはその名の通り、1つのWebサイトに対して割り当てられたクローラーの処理上限のことをいいます。
インターネット上に無数に存在するすべてのWebページをクロールすることは、クローラーのリソース上も時間的にも不可能です。限られたリソース(クローラーの処理能力)の中で、できるだけ有益なWebページをインデックスするために、クローラーは巡回の必要性をチェックします。
クロールの必要性を決定する要素
クロールの必要性を決定する重要な要素は次のとおりです。
- 検出されたURL群:不必要なページや重複コンテンツがなく、URL群がよく整理されていること
- 人気度:インターネット上で人気が高いこと
- 新しさ:情報が更新されていること
たとえば、重複しているコンテンツ、存在しないページへのリンク、ほとんど更新されない古いページなどはクロールの優先順位が下がるか、クロールされません。またページの反応が遅い場合など、通信の不具合により502などのエラーが表示されることでも、クロール頻度が下がります。
ただし、多くのWebサイトにおいて、クロールバジェットはそれほど意識しなくても問題ありません。
Googleは、重複のないページ数が100万以上のページや、1万ページ以上でほぼ毎日更新されるようなWebサイトがクロールバジェットの対象となるとしています(例:物件情報がリアルタイムで更新され、数百万件ものページがインデックスされている不動産大手サイトなど)。
参考:大規模なサイト所有者向けのクロール バジェット管理ガイド
SEOのチェックリストでWebサイトの状態を確認しよう!
クローラーとは、Webページの情報を収集するプログラムです。リンクを辿って膨大なページを巡回し、画像や単語などの情報を収集し、検索結果に反映しています。
クローラビリティ(クローラーの巡回しやすさ)を最適化する観点には、「クローラーに見つけてもらう」と「クロール効率を高める」の2つがあります。Google Search Consoleの「URL検査ツール」を使うことで、クローラーのアクセス状況を確認しながらクローラビリティを改善していくことが重要です。
Faber CompanyではSEOの状態をチェックできる101項目のチェックリストを無料で提供しています。ぜひお役立てください。

#SEO #SEO対策 #クローラー #クロール #クロールバジェット

Webディレクター、SEOコンサルタントを経て、2013年に事業会社に入社。主にBtoB領域のデジタルマーケティングに携わる。特に、リード獲得を目的とした自主調査においては7年間で累計400件以上を企画、獲得したリード数(企業の名刺情報)は述べ6万件を超える。2020年に独立。
シニアコンテンツディレクターとして、株式会社Faber Companyでも鋭意活動中。

2005年、大学卒業後、SFAベンダーに入社。コンサルタントとしてプリセールスやSFA導入プロジェクトを複数担当。2009年、CRMベンダーに入社し、営業に転身。2013年には東日本エリアセールスマネージャーに。2014年にFaber Company入社後、営業部長として売上拡大に貢献。2016年にIMC部門を新設し、ミエルカSEOを中心としたマーケティング・広報領域を統括。2020年からはミエルカSEOとローカルミエルカのプロダクトオーナーも兼務。2021年10月、執行役員就任。
▶︎ X(Twitter):@tsukky09























