シェアする



構造化データマークアップとは、ウェブページ上の情報を整理し、検索エンジンが理解しやすい形式で提供する手法です。データが構造化されることで、検索エンジンはコンテンツの意味や関連性を把握し、ユーザーに最適な検索結果や強調スニペットを提供できます。
構造化データの利用は、ウェブサイトのSEO効果を高め、より多くのユーザーに情報を届ける上で非常に重要です。本記事では構造化データのマークアップ基礎知識からメリットデメリット、設定方法などを解説していきます。

構造化マークアップの仕組み
構造化データとは、検索エンジンがWebサイトのコンテンツを理解できるようにするためのデータ形式のことです。検索エンジンにコンテンツの内容を伝えるためには、要素に目印をつけるマークアップをおこなう必要があります。
例えば、商品やのレビューを掲載しているサイトがある場合、HTMLをマークアップしていないとコンテンツのどの部分で「商品名」や「レビュー」について触れているのかを判断できません。レビュー部分をマークアップすると検索エンジンが商品のレビューをしていると判断して、検索結果にサイト内のレビューを表示するようになります。
上記のようにHTMLをマークアップして意味づけをすることで、検索エンジンがコンテンツの内容を理解できるわけです。
※参照:Google 検索セントラル「構造化データ マークアップとは」
構造化マークアップとSEOの関係性
構造化データによって、直接的に検索順位に影響を与えるわけではありません。しかし、構造化データを用いることでWebサイトのコンテンツを検索エンジンが理解できるようになります。
ユーザーが検索したキーワードに対して、コンテンツが適していればリッチリザルトに表示されやすくなるわけです。リッチリザルトに表示されれば、クリック数が自然と増え、ユーザーの集客につながります。
そのため、構造化マークアップによって検索結果に自社のサイトが表示されやすくなるので、SEO対策のひとつとして取り組むケースも多いといえます。
構造化データを理解する前に知っておきたい「セマンティックWeb」
構造化データの仕組みを理解するときに知っておきたいのが「セマンティックWeb」の考え方です。
セマンティックWebとは、Webサイトのコンテンツをただの文字列ではなく、タグ付けによって意味を定義して検索エンジンに理解してもらうことを指します。WebサイトはHTMLで記述して作成しますが、HTMLは見出しを設定したり、重要な部分を太字に装飾したりと人間がコンテンツの内容を理解できるようにするためのものです。
一方でセマンティックWebは、検索エンジンがコンテンツの内容を理解するための考え方であり、構造化データも該当します。
構造化データマークアップのメリット
構造化データマークアップのメリットとしては、以下の2つがあげられます。
- 検索エンジンがサイトのコンテンツを理解しやすくなる
- 検索結果のリッチリザルトに表示されやすくなる
それぞれ解説していきましょう。
【メリット1】検索エンジンがサイトのコンテンツを理解しやすくなる
構造化データのメリットとしては、検索エンジンがサイトのコンテンツを理解しやすくなることがあげられます。
検索エンジンは、テキストや画像にどのような意味があるのか推測することが難しく、構造化データでマークアップすることで理解できるようになります。コンテンツを理解することで、適切な情報を検索結果に表示できるようになるわけです。
【メリット2】検索結果のリッチリザルトに表示されやすくなる
構造化データを用いることで、検索結果のリッチリザルトに表示されやすくなります。リッチリザルトとは、検索結果の表示に画像や詳細なデータなどを表示する検索結果の要素です。ユーザーにより魅力的な情報を届けることができます。
たとえばリッチリザルトの種類は、以下のとおりです。
- アーティクル(ニュースやブログ記事など)
- Q&A
- よくある質問
- レシピ
- ローカルビジネス
- パンくずリスト
「クッキーの作り方」を検索したときに、検索結果の上位にクッキーの作り方の手順が詳しく表示されるわけです。リッチリザルトに表示されるとユーザーの目に留まりやすくなるので、クリック率の向上にもつながります。
構造化データでマークアップすると検索エンジンがコンテンツの内容を把握できるため、検索結果に適した内容をリッチリザルトに表示します。リッチリザルトに表示させたい場合は構造化データを用いるとよいでしょう。
構造化データのデメリット
構造化データには、検索エンジンがコンテンツを理解しやすくなるなどメリットがあるものの、一方でデメリットもあります。
構造化データのデメリットは、以下の2つです。
- 専門的な知識や技術が必要で工数がかかる
- 必ずしもリッチリザルトに表示されるわけではない
ひとつずつ説明します。
【デメリット1】専門的な知識や技術が必要で工数がかかる
構造化データでマークアップすることで、検索エンジンがコンテンツを理解できるようになるメリットがありますが、そもそも専門的な知識や技術を持っていないと構造化データのマークアップをすることは難しいといえます。
構造化データをマークアップするためには、記述方法を理解して使いこなせなければいけません。構造化データの形式によっても記述方法が違うので、常に情報をアップデートしながら習得しておく必要があります。
構造化データのマークアップ支援ツールを用いることも可能ですが、ある程度知識を持っていないと正しく設定できているか確認できません。そのため、専門的な知識や技術がなければ、想定よりも工数がかかってしまうでしょう。
【デメリット2】必ずしもリッチリザルトに表示されるわけではない
構造化データのマークアップでリッチリザルトに表示されれば、クリック率が上がり、検索エンジンからの自然流入が見込めるようになります。しかし、構造化データを用いたからといって必ずしもリッチリザルトに表示されるわけではありません。
構造化データを用いるためには、社内に知識や技術を持った人員が必要になり、設定には工数がかかります。工数ばかりかかるものの、検索流入が増えないといった状況にもなりかねないため、費用対効果が見合うかどうかを確認しておく必要があるでしょう。
構造化データを構成するボキャブラリーとシンタックス
構造化データのマークアップをする前に、構造化データの構成を理解しておきましょう。構造化データは、以下の2つの要素で構成されています。
- ボキャブラリー(定義)
- シンタックス(記述方法)
それぞれの要素について解説します。
ボキャブラリー
ボキャブラリーとは、構造化データを設定するときに使用する、情報を定義するための規格です。ボキャブラリーは、nameでは人名や名称など、addressでは住所といったように意味を定義します。
またボキャブラリーをこまかく分けると、プロパティ(属性)とバリュー(属性値)があります。例えば会社情報を記述する場合は、nameがプロパティに該当し、社名の「株式会社ファベルカンパニー」がバリューとなるわけです。
代表的なボキャブラリーとしては、GoogleやYahoo、マイクロソフトなどによって設立されたSchema.orgがあります。
Googleでは、Schema.orgのボキャブラリーが主に使用されているので、HTMLに直接マークアップする際などに確認しておくとよいでしょう。
シンタックス
シンタックスとは、ボキャブラリーに従ってHTMLにマークアップする方法のことです。
代表的なシンタックスとしては、以下の3つがあげられます。
- JSON-LD:JavaScriptのオブジェクト形式で記述、HTMLのヘッダー部分に埋め込む
- microdata:HTMLのタグに属性を追加して構造化データを記述、HTMLのボディ部分に埋め込む
- RDFa:XMLベースの言語で構造化データを記述、HTMLやXHTMLなどに埋め込む(HTML5 の拡張機能)
Googleでは、JSON-LDの使用を推奨しています。
例えば、先ほどボキャブラリーで取り上げた会社情報を記述すると以下のとおりです。
<script type=”application/ld+json”>
{
“@context”: “https://schema.org”,
“@type”: “Organization”,
“name”: “株式会社ファベルカンパニー”,
“telephone”: “+81-3-1234-5678”
}
</script>
scriptで囲んだ部分が、シンタックスに該当します。それでは、シンタックスを要素ごとに解説していきましょう。
- 「script type=”application/ld+json”」の部分で、JSON-LD形式で記述することを表しています。
- 「”@context”」は、Schema.orgで記述すると宣言しています。
- 「”@type”」で組織について書いていることがわかります。
- 「”name”: “株式会社ファベルカンパニー”」「”telephone”: “+81-3-1234-5678″」は、上記の@typeで定義した内容に対する値です。
このようにシンタックスは構造化データを正しく記述することで、検索エンジンに読み込ませる役割を持っているわけです。
構造化データをマークアップする設定方法
構造化データをマークアップする方法は、以下の2つです。
- HTMLで直接マークアップする
- マークアップ支援ツールで設定する
マークアップの設定方法によってやり方が大きく異なるため、自社に最適な方法を見極めて設定しましょう。
【方法1】HTMLで直接マークアップする
構造化データをHTMLに直接マークアップする方法をお伝えします。まず、マークアップする項目を探しておきます。例えば、以下の会社情報をマークアップするとしましょう。
- 会社名:株式会社Faber Company
- 日本語表記:「ファベルカンパニー」
- 所在地:〒105-6923 東京都港区虎ノ門4-1-1 神谷町トラストタワー 23F
JSON-LD形式でマークアップすると、以下のようになります。
<script type=”application/ld+json”>
{
“@context”: “https://schema.org”,
“@type”: “Organization”,
“name”: “株式会社Faber Company”,
“alternateName”: “ファベルカンパニー”,
“address”: {
“@type”: “PostalAddress”,
“addressCountry”: “JP”,
“postalCode”: “105-6923”,
“addressRegion”: “東京都”,
“addressLocality”: “港区虎ノ門4-1-1”,
“streetAddress”: “神谷町トラストタワー 23F”
}
}
</script>
会社名や所在地など、マークアップできる項目は、事前に確認しておきましょう。またコンテンツ内にパンくずリストがあれば、構造化データでマークアップできます。
【方法2】マークアップ支援ツールで設定する
HTMLで直接マークアップすることが難しい場合は、ツールを使ってマークアップできます。マークアップ支援ツールとして有名なのがGoogleの提供する構造化データ マークアップ支援ツールです。
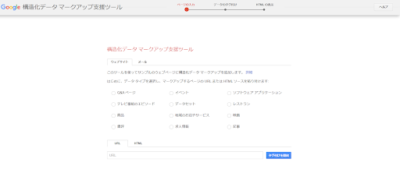
引用元:Structured Data Markup Helper
まずは、構造化データをマークアップするページのURLと情報を入力します。URLを入力するとマークアップするページが表示されます。
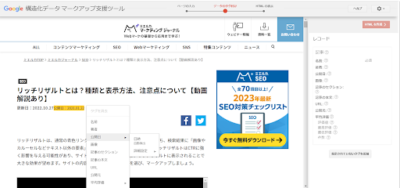
マークアップしたい箇所を選択すると、項目が表示されるので該当するものを選んで情報を記入していきましょう。
入力が済んだら「HTMLを作成」をクリックすると、JSON-LDの構造化データを出力できます。出力したHTMLをサイトに更新すれば完了です。
ただし、マークアップツールを使う場合は、マークアップの種類が限られてしまうので留意しておきましょう。
またHTMLを変更せずにマークアップしたいときは、データ ハイライターを用いてGoogleにデータのコンテンツを伝えることが可能です。
構造化データを検証する確認方法
構造化データを正しく設定できていなければ、検索エンジンがコンテンツを理解したり、リッチリザルトに表示されたりするメリットが得られません。構造化データを設定したら、まずは構造化データを検証して正しく設定できているのか確認することが重要です。
構造化データを検証する方法としては、以下の2つがあります。
- スキーマ マークアップ検証ツールを利用して確認する
- リッチリザルトテストで確認する
ひとつずつ解説していきましょう。
【方法1】リッチリザルトテストで確認する
Googleが提供するリッチリザルトテストを使用して、構造化データを検証できます。リッチリザルトテストでは、URL、またはHTMLを選んで検証することが可能です。
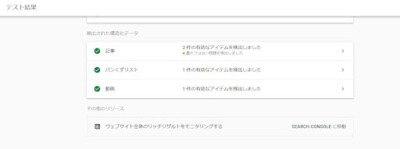
リッチリザルトテストでエラーが出ている場合は、リッチリザルトにWebページが表示されることはありません。構造化データをマークアップしたら、必ずリッチリザルトテストでエラーの表示が出ないことを確認しておきましょう。
【方法2】スキーマ マークアップ検証ツールを利用して確認する
構造化データを詳細に確認する際にはスキーマ マークアップ検証ツールを活用します。スキーマ マークアップ検証ツールでは、Schema.orgをベースにして該当ページの構造化データを検証することが可能です。
リッチリザルトテストでエラーが出た場合や、より詳細に検証する際に活用するとよいでしょう。

ミエルカ研究所は、人工知能と言語処理の力で、「言葉」の持つ可能性を追及、研究していくための研究所所長です。SEO&コンテンツマーケティング・オウンドメディア支援ツール「ミエルカSEO」をはじめデジタルマーケティングを支援するツールとサービスを提供する株式会社Faber Company(東証STD220A)が母体となってます。























