シェアする



計算型人工知能における世界的権威である高木教授が、弊社取締役の副島、執行役員の月岡、エンジニアの稲岡と対談。人工知能研究の最新情報や、生成AIがWebマーケティングに与える影響など、幅広いお話を伺うことができました。(以下敬称略)

目次

石川県金沢市出身。東京工業大学大学院 総合理工学研究科システム科学専攻、博士後期課程修了(工学博士)。1998年より、明治大学理工学部情報科学科教授(現任)。
現在、Editorial Board of Soft Computing (Springer)、Editorial Board of International Journal of Uncertainty Fuzziness and Knowledge-Based Systems (World Scientific)、 Editorial Board of Evolving Systems (Springer)。また、IEEE Computational Intelligence Society Fuzzy Systems Pioneer Award 受賞。International Fuzzy Systems Associationのフェロー。
生成AIの研究をめぐる状況
研究者が思っている以上に、生成AIは色々なことができる
副島啓一(以下、副島):
「生成AIとWebマーケティングについての対談」ということでお願いしておりましたが、まずは前提として、高木先生が現在の生成AIに対してどう感じてらっしゃるか、お聞きしてもよろしいでしょうか?
高木友博氏(以下、高木):
ChatGPTなどで注目されてる言語モデルについて言うと、「研究者が思っている以上に、実際に使える場面が広い、能力が高い」という印象があります。
私たち研究者からすれば、言語モデルは、「ただ言葉を繋げていくだけのもの」だと、どこか高を括っているところがありました。ただ、実際の動きを見ると、かなりの量のプロンプトを入力しても人のような反応を返してきますし、そこから生成できるテキストの量も増えています。むしろ、私たち研究者が「ただの言語モデルだ」と思っていることが、逆に足枷になっているのではないかと思うことがあります。これからは、「かなり人間の知能に近いものだ」と思って使わないと、その能力を使いきれないと思います。
もちろん、生成AIにできないこともたくさんあります。例えば、生成AI単体では、試行錯誤することができません。将棋の場面を見せて「どう対局を進めれば勝つか」と問いかけても、現在の生成AIは答えられないのです。こう盤面が進むとこうなる、という試行錯誤をすることができないからです。
また、過去のデータで学習した言語モデル単体では、新しい知識やニュースを知りません。厳密に言えば、新しい知識やニュースを元にした回答を生成できません。
こうした点から、「完全に人間に近いか」と言われると、そうではないと言えます。ただ裏を返せば、過去の知識を使って即答できるものについては、かなり人間に近い振る舞いをするということです。

直近の最先端は、生成AIを「どう使うか」
高木:
生成AIでできることが増えたせいなのか、最近少なくとも国内では、人工知能そのものの研究はほとんどされていない印象ですね。どちらかと言うと、モデルを使うための研究が多いような気がします。
副島:
どう使えばいいか、というものですよね。
高木:
その通りです。本来の人工知能の研究は、人間の知能の仕組みを解明して、それを機械で再現する方法を探るものです。言語モデルはあくまで、人工知能の全体像を構成する技術の一部に過ぎません。
しかし最近、生成AIの能力が高いことや、幅広いタスクをこなせるということが知られてきています。その結果として、人工知能そのものの研究とよりも、言語モデルをどう使うかと言う研究が、盛んな印象があります。
副島:
先日の人工知能学会でも、ほとんどが「言語モデルをどう使うか」にフォーカスしたものでしたね。
高木:
そもそも、現在ある言語モデルと同等のものを作ろうと思うと、膨大な資本や情報、そして頭脳が必要です。そう言う意味では、GoogleやOpen AIなどと競争できる力をもつ企業は日本にないですよね。だからこそ、少なくとも日本では「こういうモデルをどう使うか」に研究がシフトされているんだと思います。
そういう意味では、サーチエンジンと似ている気がします。Googleと同等のサーチエンジンを、日本で1から作ることが難しいから、そのサーチエンジンをどう使うか、つまりSEOで技術競争が行われると言えますよね。それと似たような現象だと思います。
副島:
サーチエンジンと似ているという点では「技術のローカライズ」が気になりますね。日本語って、英語やヨーロッパと言語体系が違うじゃないですか。以前は、サーチエンジンや人工知能の研究において、日本語の言語体系でもきちんと動くようにするにはどうしたらいいか、という研究が一定数あったのに最近はまるっきりなくなってしまったような気がします。
高木:
もちろん、日本語用の言語モデルの研究も行われています。おそらく、Googleなどがカバーしきれない、日本語の細かな部分をカバーするために作っているのだと思います。あらゆる言語に対応できるように作られた汎用性の高い言語モデルでは、日本語の能力が相対的に下がってしまい、ローカルな日本の知識が求められるような質問に答えることが、難しくなってしまうからです。
もしかしたら他の目的もあるのかもしれませんが、少なくとも、ChatGPTなどに対抗するための研究ではないと思います。多くは、「今ある言語モデルをどう使うか」にシフトしていると言えますね。
これからは、言語モデルを「部品」として使うようになる
高木:
ちなみに、この「どう使うか」という研究という中では、「生成AIのエージェント化」が始まっていることも話題になっていますね。
副島:
具体的にはどういった研究なんですか?
高木:
言語モデルは基本的に「一入力一出力」、つまり「聞いたことしか答えない」ものです。しかし人間は違いますよね。
例えば、何かを言われた時に、あるアイディアを思いついたとします。その場合、人間はそのアイディアを一旦記憶しておいて「できるかどうか」「どう実現するのか」などを推論・検証して、記憶しておいたアイディアを再度取り出してきて、検証結果と照合する、というような思考が可能ですよね。
しかし、言語モデル単体ではこうした動きは現状できません。そこで、言語モデルを全く違う機能と組み合わせることで、こうした人間の思考らしい動きをやれるようになるんじゃないか、という研究がたくさん出てきています。言語モデルの生成した回答を、覚えておいたり整合性を確かめる機能を別で作るということですね。これでできることの幅がかなり広がります。
例えば、まだ研究段階ではありますけれども、言語モデルを他の部品と組み合わせることで、より人間らしいシュミレータを作る、というようことが可能です。
副島:
「人間らしいシュミレータ」ですか?
高木:
わかりやすくいうと、言語モデルに付随する形で、試行錯誤する部品や、アイディアを貯めておく部品を組み合わせることで、より人間の思考や行動に沿ったシュミレータを作る、というものです。このシュミレータにおける言語モデルは「何かを問いかけられたら回答する」という、知識システムを担当する部品になるということですね。
今までのシュミレータは、行動ルールを人工的に決めて作られるものがほとんどだったので、そこから出力されるシュミレーション結果も、人工的で現実味のない出力になっていました。例えば「家で火事が起きたら逃げる」というルールに沿って作られたシュミレータでは、火事が起きた瞬間に家族全員が逃げる、というシュミレーション結果になります。ある意味、本当のシュミレーションとは言えないでしょう。なぜなら、実際の人間の思考や行動はもっと複雑だからです。
普通、家で火事が起きた時、人間は「家族が心配だから、他の部屋を見に行く」「こっちに行ったら人が多くて逃げられないから、わざと人通りのない狭い道を選ぶ」というように、状況に応じて様々な思考が行われ、その結果としてかなり複雑な行動を取りますよね。言語モデルであれば、このような人間らしい行動を生成させることができるので、はるかにリアリティを持ったシュミレータとして使うことができるんです。
シュミレータはあくまで一例ですが、このように言語モデルは、今までの機械学習よりできることのバリエーションがかなり多いのです。
副島:
すごいですね。

生成AIのマルチモーダル化
画像や音声での入出力
月岡克博(以下、月岡):
最新の生成AIでは、画像や動画だけでなく「今からアニメを作ります、主人公はライオンです、悪役は蛇です」といった指示を出していくと、ライオンっぽい声やこわい悪役みたいな蛇の声を生成する、ということもできるようになってきています。こういった画像や音声の形でのアウトプットも、言語モデルが使われているんですか?
高木:
もともとの言語モデルは、言語入力に対し言語を出力するものでした。しかし今では、マルチモーダル化が進み、画像や音声の入力を受け付けるようになっています。また、 画像と言語を互いに紐付けることも既に終わっていて、一方から他方への変換も自由に行えますし、画像と言語を混ぜて処理することもできます。
いずれにせよ、画像や音声の入出力は今後どんどんできるようになっていくはずですし、精度も上がるはずです。我々研究者も、そういうことができるようになるという前提で研究を進めていくことになりますね。
生成AI事業は「アノテーション」が鍵?
月岡:
そういった、画像や音声の入出力の際は「この画像は、椅子の画像である」というアノテーション(タグ付け)はどこから来ているんですか?
高木:
すでに学習済みなので、アノテーション自体は不要です。Web上で、alt属性に椅子と書いてある椅子の画像は大量にありますよね?つまり、すでにアノテーションされたWeb上のデータを大量に学習しているので、そこで判断できるようになっています。たまに違うものもありますが、量が増えれば増えるほど、そういったノイズは消されていくので、精度は上がっていきます。
ただし、機械学習する量が増えれば増えるほど、判別がつけられないグレーゾーンの部分も増えていくことになります。そこを判断させたいという需要はどんどん増えていくと思います。
月岡:
アノテーションするだけのサービスを提供する会社もありそうですね。
稲岡夢人(以下、稲岡):
特定のドメインや、医療系でよくある「心臓の画像」のようなクローズドデータは、特にアノテーションする必要がありますよね。
高木:
逆にそういうニッチなところをサービスにしていると、事業として成長性が高いかもしれないですね。
高木:
そうですね。一般的なデータは、アメリカの大企業が一斉にアノテーションしていますから、日本の一企業がやっても太刀打ちはできません。しかし、そういったニッチな分野であれば、いくらでも事業的なチャンスはあると思います。
生成AIは、「データ生成」と「データ分析」に使うべき
生成AIの強み①「リアリティをもった対応」
高木:
現在の生成AIは、場面やタイミングによって、感情的なテキストを生成することも可能になってきていますよね。こうした感情を含むテキストは、どういうロジックで出てくるんですか?
高木:
あれは「普通の人が、もしそう言う場面でそういうことを言われたら、このように言うだろう」ということを再現しているだけなんです。実は「感情のマネ」はとても簡単なんですよ。「こんなことを言ったら怒るかな」とか「こんなことを言ったら悲しむかな」とか、そういうことを学習させるだけなので。
月岡:
感情を持っているわけではなく、あくまで反応の延長線、ということですか?
高木:
その通りです。今までの機械学習では、1対1の対応関係が基本でした。「こう言ったら怒る」「こう言ったら泣く」というふうに、単純なルールに沿って出力が決められていたので、生成される結果も単純だったのです。
しかし今の言語モデルでは、どんな状況が考えられるか、それに対してどういった反応が考えられるか、といったことが、事前に大量に学習されているので、わざわざ人間側でルールを作って覚えさせる必要がないのです。これにより、複雑な状況下でも人間のような振る舞いをすることが可能になりました。
そして、こうしたリアリティを持った対応ができる技術は、Webマーケティングでも利用することができます。例えば、顧客のペルソナを作って「こういう顧客に対してこう言ったらどう反応するか」というシュミレーションをすることもできますし、リアルな顧客データを生成させることも可能です。実は、私の研究室でも、データ生成の研究をやっているんですよ。
副島:
面白そうですね!具体的にはどういうものなんですか?
高木:
わかりやすく言えば「購入履歴の生成」ですね。「誰が・いつ・どこで・何を・いくらで買ったか」というデータです。これを生成AIに生成させれば、機械学習に利用することができます。
さらに様々なペルソナをランダムに発生させます。「何歳」「どんな職業か」「どこに住んでいるか」「将来どうなりたいか」などを、生成AIに勝手に発生させるのです。そして、それぞれのペルソナについて「その人はどういう買い物をしますか?」と質問して、答えさせます。それを繰り返せば、特定の人に1000回買い物させたり、あるいは膨大な数の人に買い物をさせることができるので「誰が・いつ・どこで・何を・いくらで買ったか」というデータが新たに溜まっていくわけです。
副島:
リアルに買い物をさせなくても、購入データを獲得することができる、ということですか?
高木:
そうです。もちろん、望むデータを生成してもらうために、プロンプトなどのセッティングはきちんと考える必要があります。ただし、セッティングさえきちんと作って仕舞えば、ペルソナが勝手に買い物してくれるので、わざわざ実データを集める必要が無くなるのです。
今までは、ペルソナを作っても、リアリティ溢れる背景知識が言語モデルになかったので、「20代の学生なら、こんなものを買うだろう」というルールを作っておく必要があったんです。なので、生成される人工的なデータも、とても単純で人工的でした。でも今は、リアリティ溢れる背景知識が言語モデルにあるので、それに伴って、リアリティ溢れる人工データを作れるようになったのです。
月岡:
その「リアリティさ」は、どう検証できるんですか?
高木:
例えば「本当のデータと生成させたデータを区別できるか」どうかなどで検証できます。実際、区別できないくらいまでになっているんです。
一般的に、ChatGPTは、「喋るもの」というふうに捉えられていますよね。ほとんどの方は、ChatGPTを、何かを聞いて、何かを答えさせるものとして使っているのではないかと思います。しかし、ChatGPT利用の最先端では、こういったデータ生成などが行われようとしています。これによって、「やりたかったのに、データがないので実現できず困っていた」という作業ができるようになります。
生成AIの強み②「解釈する力」
高木:
またデータ生成だけでなく、データ解析でも言語モデルが大いに利用できるのではないかと言われています。わかりやすく言えば、言語モデルにデータを入力することで、そのデータを解釈させるというものです。言語モデルは、リアリティ溢れる背景知識を豊富に持っているので、より人間の感情や思考に近い形で、データを解釈できるようになるのではないかと言われています。
月岡:
アクセス解析もデータを用いますよね。将来的には「どういう感情でクリックしたか」などもわかるようになるんですか?
高木:
そこはまだ、これから開発されていくところなんですが、できるようになるはずだと言われています。今までは人間が目を皿のようにして見ていたデータを、人間が理解しやすい形で解釈できるようになる、ということですね。
稲岡:
つまり、セッティングさえうまく行ってしまえば「AIに生成させたデータを、AIに分析させる」ということが可能、ということですか?
高木:
その通りです。データの生成と分析という、一見対極にある作業がどちらもできるようになるということです。

人間と生成AIは「協業」すべき
人間の役割は「感覚器官」
月岡:
生成AIのできることがこれほどまでに幅広いとなると、今後人間の活躍の仕方がかなり変化していくような気がします。結局のところ、生成AIに任せることと人間がやらなければいけないことは、どう分ければいいんでしょうか?
高木:
私が考えるには「完全に協業」ですね。言語モデルでできることはたくさんありますが、AI一本ではだめです。そもそも言語モデルは、人間が何か話しかけないことには答えないですし、データや条件などいった情報を人間が与えないと、望む答えを得られないからです。
もちろん、全てを機械に任せたいというニーズも確かにあります。しかし結局のところ、機械は人間が作った範囲でしか動かないので、それを人間が監視したり、他の情報と組み合わせて考える必要があるのです。
例えば、生成AIにあるデータを解釈させた時、どこか不自然な結果になったとします。この時、人間なら「そういえば、この間ジャイアンツ戦やってたから、こんな結果になったのかもしれないね」といった、生活から来る気づきを得ることができます。
しかし生成AIは、与えられたデータを与えられた情報の中で解釈しているだけなので、こうした気づきを得ることはできません。人間が仕事をする際、特にマーケティングなどでは、そういった気づきはどうしても必要ですよね。だから、生成AI一本ではだめなのです。
月岡:
逆に言えば、生活のあらゆる方向にアンテナを張っていられる人間でないと、マーケティングはできない、ということでしょうね。
稲岡:
そういう点では「言語モデルの周辺に部品をつけて、より高度なシュミレータを作る」という話と似ていますね。日常生活を送っている人間だからこそわかる情報を与える「感覚器官」として人間が関わっていくということですね。
高木:
そうですね。逆に、パターン化した業務や、単純作業のようなものはどんどん生成AIにやらせないと、競争力がなくなっていくと思います。生成AIの方が正確ですし、早いので、生産性が高くなるのです。そういった部分での生成AIの導入は、どんどん進めた方が良いと思いますね。

(おまけ)生成AIが記事原案を執筆!AIコンテンツアシスト機能
今回は、生成AIに関する対談をお送りしましたが、今後の生成AI活用イメージは湧きましたでしょうか。ちなみに、ミエルカSEOでは狙っているキーワードと記事の見出しを入力するだけで、記事の原案を自動で生成することができる機能を提供しています。
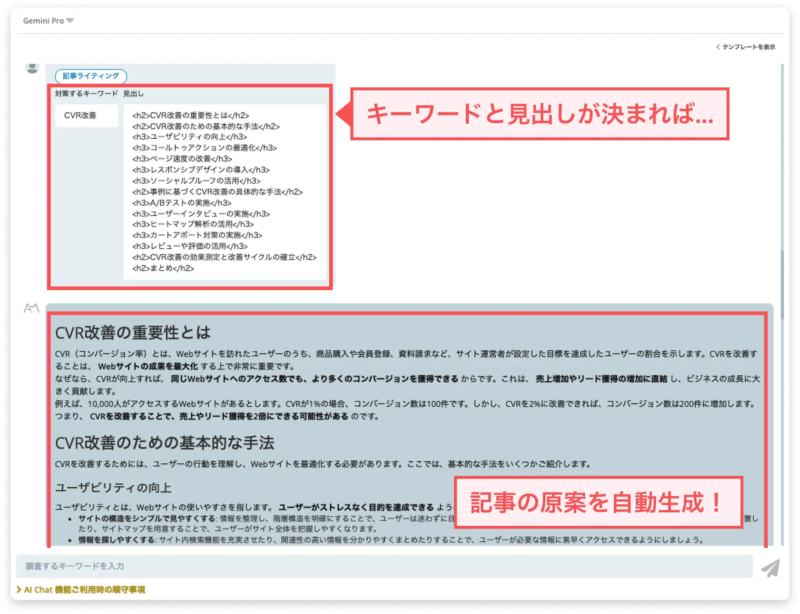
GPT-3.5, GPT-4, Gemini PRO, Claude の4つの異なるモデルを利用可能で、指示するタスクに合わせて最適な生成AIモデルを選択できます。さらに、これらのモデルを利用する際の制限もありません。また、入力データは各種モデルに学習されないよう設定されているため、入力データの漏洩などを気にせず安心してご利用いただけます。
無料トライアルも受け付けております。ご興味のある方は、以下からお申し込みください!
対談者PROFILE
石川県金沢市出身。東京工業大学大学院 総合理工学研究科システム科学専攻、博士後期課程修了(工学博士)。
明治大学理工学部情報科学科 教授。計算型AIの世界トップクラスの権威であると同時に、
#生成AI #SEO #ミエルカ

株式会社Faber Companyに新卒入社した後、ミエルカマーケティングジャーナルの執筆や自社ソフトウェアの開発ディレクション業務に携わる。
現在は、ミエルカSEOの新機能開発ディレクションや、リリースした機能のプロモーション業務を中心に担いながら、社内外で登壇活動も行っている。
▶︎X(Twitter):@manaty_takady























